Chenyang Zhu
朱晨阳
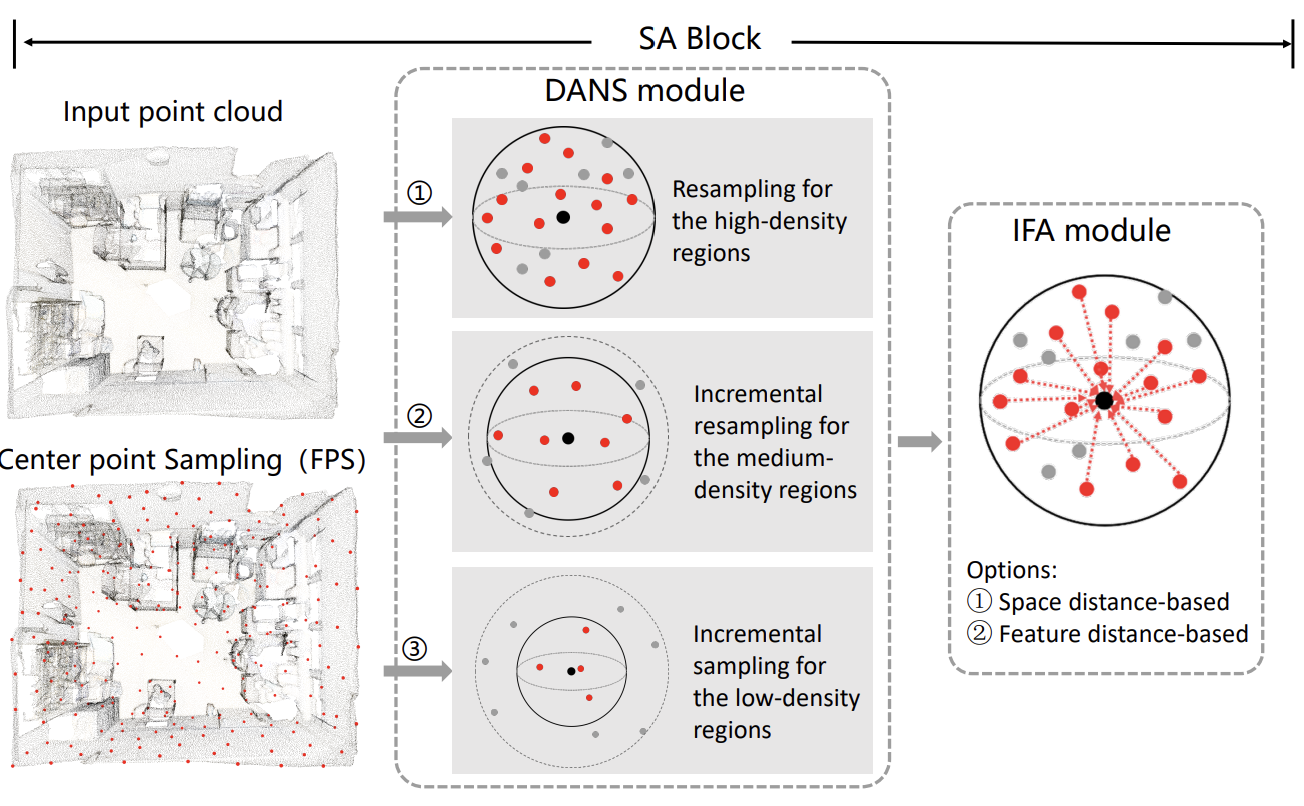
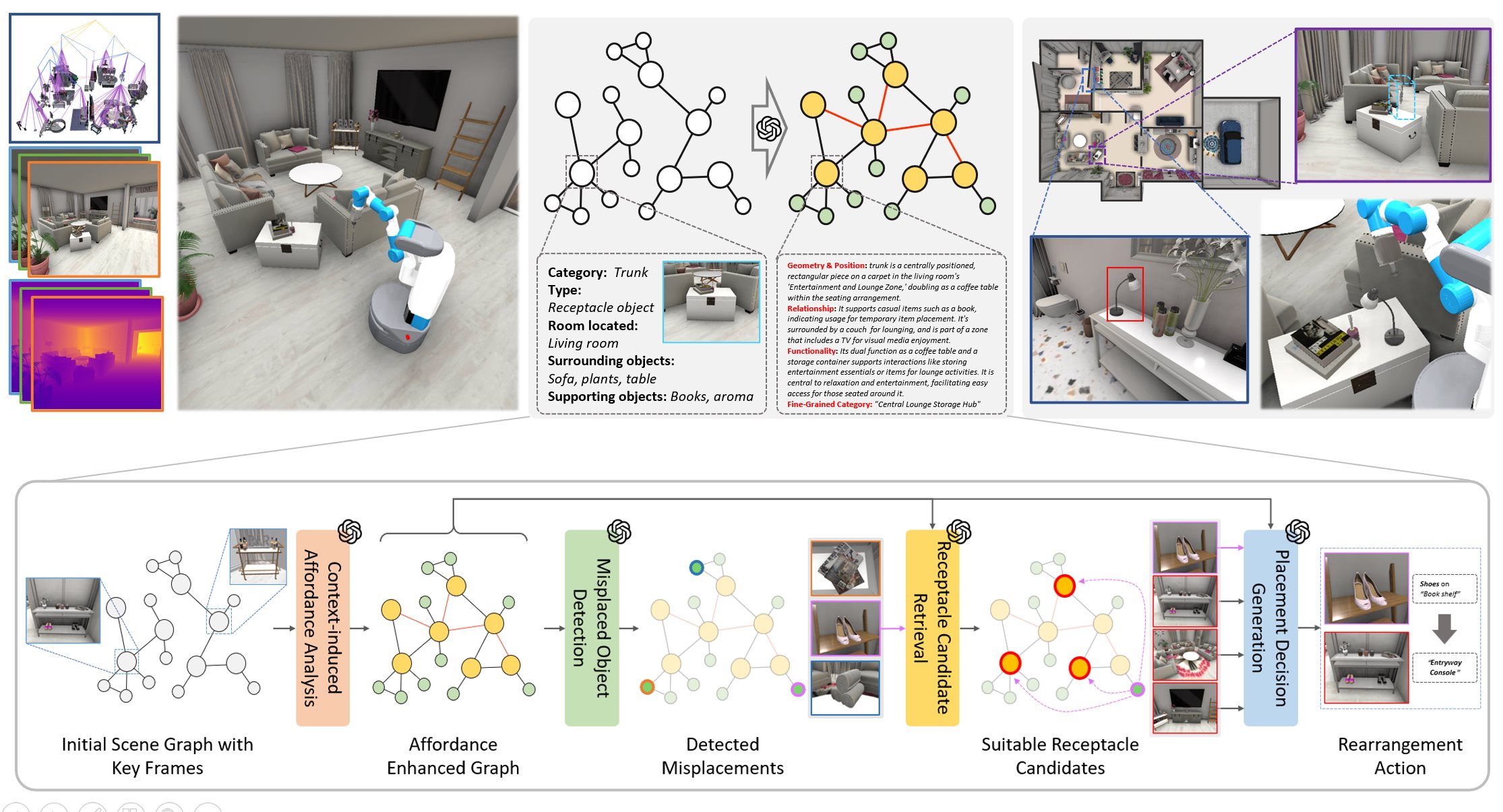
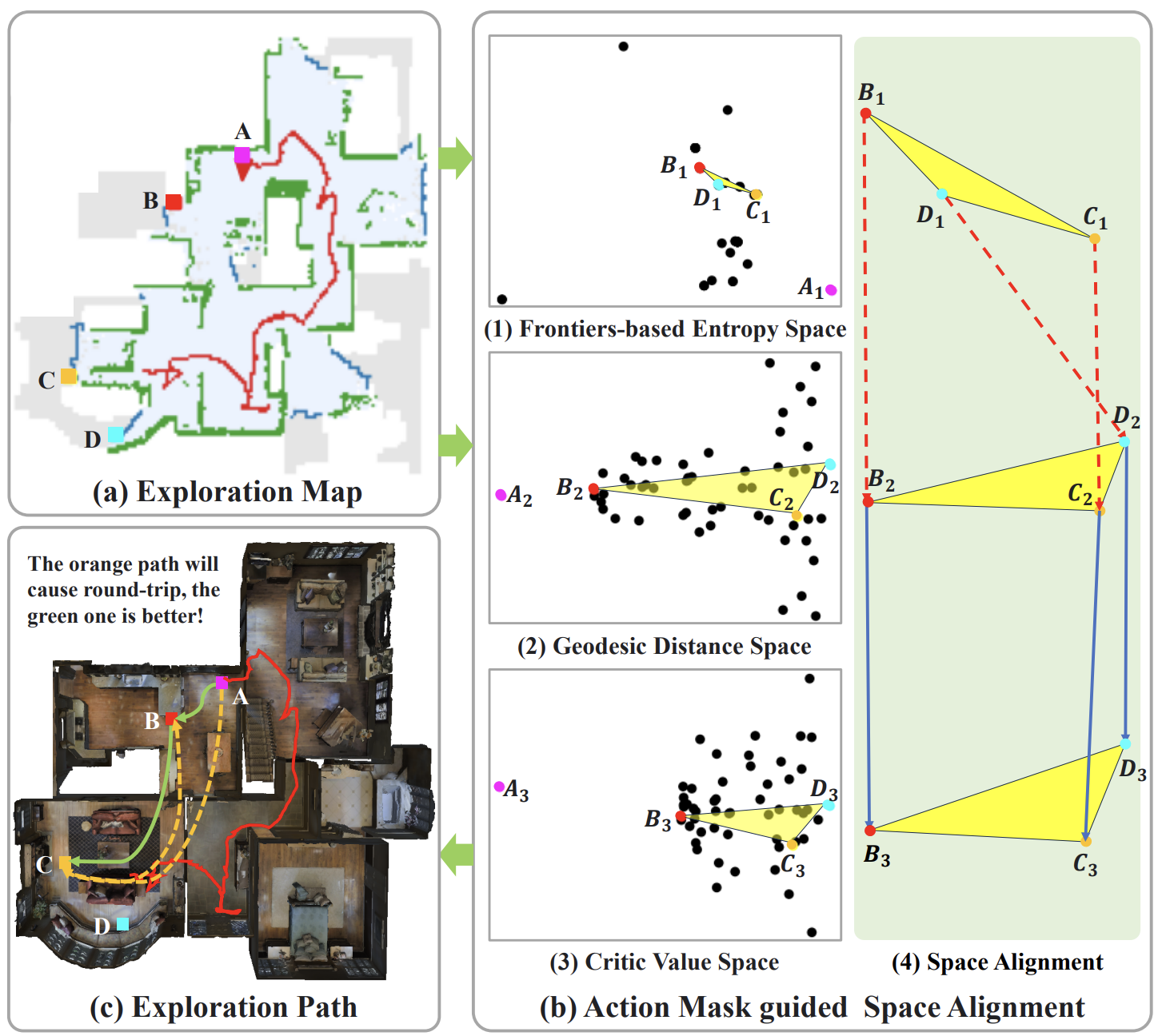
My name is Chenyang Zhu. I am currently a Full Professor at School of Computer Science, National University of Defense Technology (NUDT). I am a faculty member of iGrape Lab @ NUDT, which conducts research in the areas of computer graphics and computer vision. The current directions of interest include data-driven shape analysis and modeling, 3D vision and robot perception & navigation, etc.
I was a Ph.D. student in Gruvi Lab, school of Computing Science at Simon Fraser University, under the supervision of Prof. Hao(Richard) Zhang. I earned my Bachelor and Master degree in computer science from National University of Defense Technology (NUDT) in Jun. 2011 and Dec. 2013 respectively.